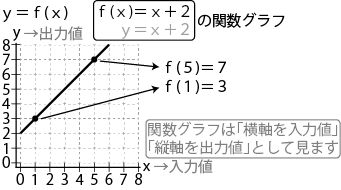
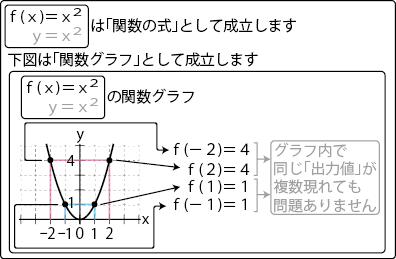
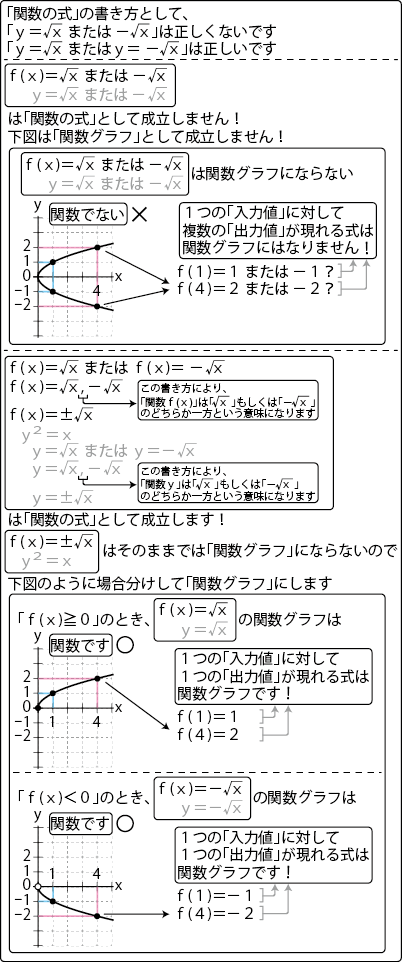
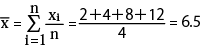C# 統計・微分積分・線形代数への道
目次→http://1studying.blogspot.jp/2017/08/senkei-index.html#kuw04
「統計の基本」
メモっておく。
ここでは、
「×」を「*」
「÷」や「分数」を「/」
で表現します。
「偏差値」とは…
「偏差値」を使えば、
テストなどで「全体の平均点」を「偏差値50」とした場合、
自分の点数が相対的にどれ位高いのか、もしくは低いのかを分析できます。
「偏差値」の定義は以下のような物です。

これを「偏差値」を求める計算式に直すと

となります。
計算例:(偏差値)
「xi」の要素がそれぞれ
「x1=2」「x2=4」「x3=8」「x4=12」
として、
まずは「平均(average)」を計算します。

よって、「平均(average)」が「6.5」と分かりました。
次に「標準偏差σ」を計算します。

よって、「標準偏差σ」が「3.840572874…」と分かりました。
ここから、
「x4=12」の「偏差値」を計算して見ましょう。

よって、
「x4=12」の「偏差値T4」は「約64.32」
となります。
「偏差値計算」
参考→http://keisan.casio.jp/exec/system/1308268612
「偏差値」の「各要素の分布」が「正規分布」にならないとき
「正規分布」に従って「偏差値」を考えた時、
ある偏差値以上の人のいる割合は何パーセントか(「各要素の出現率」)
つまり、
「その偏差値は上位約何%か」の目安は以下のような形となります。
「偏差値75」の人は「上位約0.6%」の人間
と判断できます。
但しこの判断は、
「各要素の分布」が「正規分布」(ベル型)に近い形状である場合に限る
「正規分布」に従った場合に限る
事に注意して下さい。
「偏差値」のような「平均を50とした時の相対値」を重視する数値では、
「各要素の分布」が「正規分布」(ベル型)と違う「偏った分布」であっても
許容してそのまま計算を行います。
その場合「偏差値」としては正しい数値と言えるのですが、
理想的な分布では無い為、
当然「正規分布」(ベル型)の「各要素の出現率」による判断に当てはまらなくなります。
繰り返しになりますが、
「偏差値」とは平均の時を50とした場合を指標として、
平均からどれだけ離れているのかを分析する為の値
「正規分布」とは各要素の分布か確率的に収束するべきである理想的な分布の形
です。
「偏差値」は「正規分布」の形を理想とした値ではありますが、
「正規分布」の形でなくても「偏差値」は「偏差値」です。
「基準値(基準化)」「標準値(標準化)」
「基準値」「標準値」は同じ意味の言葉です。
「複数の要素の数値」を「基準値に変換、標準値に変換」する事を
「基準化する、標準化する」と呼ぶのですが、
ここでは、
「標準値に変換」「標準化する」
の言い方に統一して説明を行って行きます。
「標準値、標準化」とは
「標準化」により「標準値」を得る事により、
集合(配列)の数値の中の1つの数値が
その集合(配列)の平均を0とした時に
相対的にどの位置にいるのか
を知る事が出来ます。
「標準値」を求める計算式は以下のようになります。

「平均 = 0、標準偏差σ = 1、分散 = 1」とした場合の
1要素の値「標準値i」が求まります。
ちなみに「標準値」に「*10倍して50を足した」のが「偏差値」です。
計算例:(標準値、標準化)
「xi」の要素がそれぞれ
「x1=2」「x2=4」「x3=8」「x4=12」
として、
まずは「平均(average)」を計算します。

よって、「平均(average)」が「6.5」と分かりました。
次に「分散」と「標準偏差σ」を計算します。

よって、
「分散」が「14.75」
「標準偏差σ」が「3.840572874…」
と分かりました。
ここから、
「x4=12」の「標準値」を計算して見ましょう。

このようにして、
「x1」〜「x4」の「標準値」を計算した結果が以下の表です。

「標準化」した「x1」〜「x4」から
「平均」を求めると「平均=0」
「分散」を求めると「分散=1」
「標準偏差σ」を求めると「標準偏差σ=1」
である事が分かります。
「標準化」すると
「平均」が「標準値が0」となり
「平均」より要素の値が低いと「標準値が−マイナス」
「平均」より要素の値が高いと「標準値が+プラス」
となります。
「標準化」した「正規分布」は以下のイメージとなります。

「偏差値」の「正規分布」イメージと見比べてみて下さい。

「標準化」した「正規分布」に「*10倍して50を足した」のが「偏差値」です。
「標準偏差や分散」で「母」「標本」「不偏」などが頭に付いたときや、
それらを表すアルファベット記号の違いが混乱しやすく感じます。
「不偏分散u2」「不偏標準偏差u」について学ぶついでに整理していきます。
「母集団」と「標本」(推測統計とは)
「母集団」は「要素全体」を指します。
「標本」は「母集団の中から抽出した一部の要素全体」を指します。
「標本」から「母集団」の状態を推測する事を「推測統計」と言います。
何を「母集団」として、その中のどの範囲を「標本」と捉えるかは判断により変わり、
この判断によっては後の計算結果の信頼度にも影響します。
選挙の出口調査や政党支持率予想、アンケートなどで母集団の「推測」を行っても、
調査機関や調査方法により推測と実体が違ってしまう事があるのはこの為です。
「標本(サンプル)」の取捨選択はプロの調査機関でも判断が難しい問題なのです。
「母平均μ」「標本平均x−」
「母集団」の平均が「母平均μ(ミュー)」、
「標本」の平均が「標本平均x−」です。
「母平均」と「標本平均x−」は同じ計算式で良い決まりです。
「母集団」の平均と「標本」の平均では値が近くなる為です。

これを踏まえて「分散」の説明をします。
「母分散σ2」と「標本分散s2」と「不偏分散u2」
「分散」とは各要素の「バラツキ度」の事です。
本来「分散」は「母分散σ2」を使用して計算を行うのが正しいのですが、
「統計」では常に「母集合」全ての値を取得できる状態では無い場合や、
全てを計算するコストを掛けられない事がよくあります。
そのような時は複数の「標本(サンプル)」要素から計算して、
「母分散σ2」を推測する必要が出てきます。
まず、式の違いを見て下さい。
・「母分散σ2」
・「標本分散s2」
「sample variance、標本のバランス」のイニシャル「s」を使用。
・「不偏分散u2」(標本不偏分散u2)
「unbiased variance、公平なバランス」のイニシャル「u」を使用。
・「分散V[X]」
「母分散」の「標本(サンプル)」である「標本分散s2」は、
「標本となる要素数」が少ないと「母分散σ2」より数値が小さくなります。
これを、より「母分散σ2」に近づける為に
分母に「−1」の「補正」を加えたのが「不偏分散u2」です。
ここからがややこしいのですが、
一部の書物やWebでは
「不偏分散u2」の式を「標本分散s2」として紹介や表記する事例をよく目にします。
厳密にはこの定義式の表記方法でも間違えではないのですが、
「補正」の入っていない「標本分散s2」
「補正」の入った「不偏分散u2」
は区別して理解しておいた方が後々混乱しにくいと思います。
この形で覚えておいた方が良いでしょう。
その上で混同使用される事があるという現状を知っておいて下さい。
また、
「標本分散s2」や「不偏分散u2」の式を「標本(サンプル)」として扱わないで、
最初から「母分散σ2」に見立てた前提で「分散σ2」と記述を行って
説明される事がよくあります。
これらを踏まえて「標準偏差」の説明をします。
「母標準偏差σ」と「標本標準偏差s」と「不偏標準偏差u」
「標準偏差」とは「√分散」の計算を行った「バラツキ度」の事です。
本来「標準偏差」は「母分散σ2」を使い「母標準偏差σ」を計算するのが正しいのですが、
それがままならない時は「標本分散s2」や「不偏分散u2」から「標準偏差」を推測します。
式の違いを見て下さい。
・「母標準偏差σ」
・「標本標準偏差s」(標本偏差s)
「sample variance、標本のバランス」のイニシャル「s」を使用。
・「不偏標準偏差u」(不偏標本標準偏差u)
「unbiased variance、公平なバランス」のイニシャル「u」を使用。
「母標準偏差σ」「標本標準偏差s」「不偏標準偏差u」の違いは
「母分散σ2」「標本分散s2」「不偏分散u2」の違いに準じる形となり、
結果、以下のような事が言えます。
「母標準偏差σ」の「標本(サンプル)」である「標本標準偏差s」は
「標本となる要素数」が少ないと「母標準偏差σ」より数値が小さくなります。
これを、より「母標準偏差σ」に近づける為に
分母に「−1」の「補正」を加えたのが「不偏標準偏差u」です。
(「補正」とは分母の観測個数nから1を引く事を指します)
「分散」の時と同様に「標準偏差」でも以下の使われ方をする事があります。
「不偏標準偏差u」を「標本標準偏差s」として「補正」折り込み済みで
紹介や表記する事例がある。
「標本標準偏差s」や「不偏標準偏差u」の式を「母標準偏差σ」と見立てて
「標準偏差σ」として説明する事がある。
混乱しやすい部分なので気をつけて下さい。
「平均値(アベレージ)」「中央値(メジアン)」「最頻値(モード)」
・「平均値、算術平均」(アベレージ)
「全部の要素の数字を足してから要素の数で割ったもの」
が「平均値」です。「算術平均」とも言われます。
・「中央値」(メジアン)
「昇順か降順に要素の数字を並べた時、中心に来る値」
が「中央値」です。
・「最頻値」(モード)
「一番出現回数の多い要素の数値」もしくは「一番出現回数の多い範囲」
が「最頻値」です。
分布図による「平均値、中央値、最頻値」のパターン
分布図の形によって、
「平均値(アベレージ)」「中央値(メジアン)」「最頻値(モード)」に
大体以下の違いが出ます。
・中央が盛り上がった山型の分布図

「平均値、中央値、最頻値」が山の中心付近に集まる特性がある。
「正規分布」の理想的な形(ベル型)です。
・片側に盛り上がった山型の分布図

山の峰から「最頻値、中央値、平均値」の順に並びやすい特性がある。
C# 統計・微分積分・線形代数への道
次へ→http://1studying.blogspot.jp/2017/08/senkei-index.html#kuw05
以下のサイトを参考にしました。
標準正規確率表(σの確率表)
http://aoki2.si.gunma-u.ac.jp/lecture/Bunpu/normdist/hyojunka.html#tab1
偏差値とは何かをおさらい!意味・求め方・正規分布との関係性のまとめ
https://atarimae.biz/archives/9109
分散の求め方と公式。その有用性について
https://atarimae.biz/archives/8782
不偏標準偏差の出し方
https://detail.chiebukuro.yahoo.co.jp/qa/question_detail/q11148040646
統計学における分散と不偏分散 例題でわかりやすく解説
https://to-kei.net/basic/glossary/variance/
不偏標本分散の意味とn-1で割ることの証明
https://mathtrain.jp/huhenbunsan
勘違いしやすい統計用語の定義。標本の大きさと標本数・母数・不偏標準偏差など
https://atarimae.biz/archives/10319
統計のウソ
http://ronri2.web.fc2.com/tokei.html
http://ronri2.web.fc2.com/tokei04.html
「12-5. 確率変数の分散」
https://bellcurve.jp/statistics/course/6716.html
さまざまな確率分布
http://www.biwako.shiga-u.ac.jp/sensei/mnaka/ut/statdist.html
統計web:統計学の時間
https://bellcurve.jp/statistics/course/
数学記号の表
https://ja.wikipedia.org/wiki/%E6%95%B0%E5%AD%A6%E8%A8%98%E5%8F%B7%E3%81%AE%E8%A1%A8
数式記号の読み方・表し方
http://izumi-math.jp/sanae/report/suusiki/suusiki.htm
目次→http://1studying.blogspot.jp/2017/08/senkei-index.html#kuw04
「統計の基本」
メモっておく。
ここでは、
「×」を「*」
「÷」や「分数」を「/」
で表現します。
「偏差値」の計算
「偏差値」とは…
「偏差値」を使えば、
テストなどで「全体の平均点」を「偏差値50」とした場合、
自分の点数が相対的にどれ位高いのか、もしくは低いのかを分析できます。
「偏差値」の定義は以下のような物です。
・「正規分布」に「全ての要素」の数値(テストの点数など)を当てはめる
・「平均」を「偏差値50」に固定
・「標準偏差σ(バラツキ度)」1つ分を「偏差値10の変化」、
として変換して求めた数値が
「偏差値」となります。
「正規分布」では以下のイメージとなります。・「平均」を「偏差値50」に固定
・「標準偏差σ(バラツキ度)」1つ分を「偏差値10の変化」、
として変換して求めた数値が
「偏差値」となります。
これを「偏差値」を求める計算式に直すと
となります。
計算例:(偏差値)
「xi」の要素がそれぞれ
「x1=2」「x2=4」「x3=8」「x4=12」
として、
まずは「平均(average)」を計算します。

よって、「平均(average)」が「6.5」と分かりました。
次に「標準偏差σ」を計算します。
よって、「標準偏差σ」が「3.840572874…」と分かりました。
ここから、
「x4=12」の「偏差値」を計算して見ましょう。

よって、
「x4=12」の「偏差値T4」は「約64.32」
となります。
「偏差値計算」
参考→http://keisan.casio.jp/exec/system/1308268612
「偏差値」の「各要素の分布」が「正規分布」にならないとき
「正規分布」に従って「偏差値」を考えた時、
ある偏差値以上の人のいる割合は何パーセントか(「各要素の出現率」)
つまり、
「その偏差値は上位約何%か」の目安は以下のような形となります。
・偏差値「各要素の出現率」
80(0.13%)、75(0.6%)、70(2.2%)、65(6.6%)、
60(15.8%)、55(30.8%)、50(50%)、45(69.2%)、40(84.2%)、
35(93.4%)、30(97.8%)、25(99.4%)、20(99.87%)
「正規分布」に従うと80(0.13%)、75(0.6%)、70(2.2%)、65(6.6%)、
60(15.8%)、55(30.8%)、50(50%)、45(69.2%)、40(84.2%)、
35(93.4%)、30(97.8%)、25(99.4%)、20(99.87%)
「偏差値75」の人は「上位約0.6%」の人間
と判断できます。
但しこの判断は、
「各要素の分布」が「正規分布」(ベル型)に近い形状である場合に限る
「正規分布」に従った場合に限る
事に注意して下さい。
「偏差値」のような「平均を50とした時の相対値」を重視する数値では、
「各要素の分布」が「正規分布」(ベル型)と違う「偏った分布」であっても
許容してそのまま計算を行います。
その場合「偏差値」としては正しい数値と言えるのですが、
理想的な分布では無い為、
当然「正規分布」(ベル型)の「各要素の出現率」による判断に当てはまらなくなります。
繰り返しになりますが、
「偏差値」とは平均の時を50とした場合を指標として、
平均からどれだけ離れているのかを分析する為の値
「正規分布」とは各要素の分布か確率的に収束するべきである理想的な分布の形
です。
「偏差値」は「正規分布」の形を理想とした値ではありますが、
「正規分布」の形でなくても「偏差値」は「偏差値」です。
基準値、標準値(基準化、標準化)
「基準値(基準化)」「標準値(標準化)」
「基準値」「標準値」は同じ意味の言葉です。
「複数の要素の数値」を「基準値に変換、標準値に変換」する事を
「基準化する、標準化する」と呼ぶのですが、
ここでは、
「標準値に変換」「標準化する」
の言い方に統一して説明を行って行きます。
「標準値、標準化」とは
「標準化」とは「複数の要素の数値群」を
「平均を0、標準偏差σを1(分散を1)」
となるように調整して変換する事です
変換後の値が「標準値」となります。「平均を0、標準偏差σを1(分散を1)」
となるように調整して変換する事です
「標準化」により「標準値」を得る事により、
集合(配列)の数値の中の1つの数値が
その集合(配列)の平均を0とした時に
相対的にどの位置にいるのか
を知る事が出来ます。
「標準値」を求める計算式は以下のようになります。

「平均 = 0、標準偏差σ = 1、分散 = 1」とした場合の
1要素の値「標準値i」が求まります。
ちなみに「標準値」に「*10倍して50を足した」のが「偏差値」です。
計算例:(標準値、標準化)
「xi」の要素がそれぞれ
「x1=2」「x2=4」「x3=8」「x4=12」
として、
まずは「平均(average)」を計算します。

よって、「平均(average)」が「6.5」と分かりました。
次に「分散」と「標準偏差σ」を計算します。
よって、
「分散」が「14.75」
「標準偏差σ」が「3.840572874…」
と分かりました。
ここから、
「x4=12」の「標準値」を計算して見ましょう。

このようにして、
「x1」〜「x4」の「標準値」を計算した結果が以下の表です。
「標準化」した「x1」〜「x4」から
「平均」を求めると「平均=0」
「分散」を求めると「分散=1」
「標準偏差σ」を求めると「標準偏差σ=1」
である事が分かります。
「標準化」すると
「平均」が「標準値が0」となり
「平均」より要素の値が低いと「標準値が−マイナス」
「平均」より要素の値が高いと「標準値が+プラス」
となります。
「標準化」した「正規分布」は以下のイメージとなります。
「偏差値」の「正規分布」イメージと見比べてみて下さい。
「標準化」した「正規分布」に「*10倍して50を足した」のが「偏差値」です。
「分散と不偏分散」「標準偏差と不偏標準偏差」
「標準偏差や分散」で「母」「標本」「不偏」などが頭に付いたときや、
それらを表すアルファベット記号の違いが混乱しやすく感じます。
「不偏分散u2」「不偏標準偏差u」について学ぶついでに整理していきます。
「母集団」と「標本」(推測統計とは)
「母集団」は「要素全体」を指します。
「標本」は「母集団の中から抽出した一部の要素全体」を指します。
「標本」から「母集団」の状態を推測する事を「推測統計」と言います。
「母集団」…「標本」の例
「 全ジャンプ読者」…「 ジャンプ読者内でアンケートはがきを送った人々」
「 全TV視聴者の世帯」…「 TVの視聴率調査に協力している世帯」
「全世界の高校3年生の偏差値」…「日本全国の高校3年生の偏差値」
「 日本全国の高校3年生の偏差値」… 「高校3年生1クラス内の偏差値」
実際、「 全ジャンプ読者」…「 ジャンプ読者内でアンケートはがきを送った人々」
「 全TV視聴者の世帯」…「 TVの視聴率調査に協力している世帯」
「全世界の高校3年生の偏差値」…「日本全国の高校3年生の偏差値」
「 日本全国の高校3年生の偏差値」… 「高校3年生1クラス内の偏差値」
何を「母集団」として、その中のどの範囲を「標本」と捉えるかは判断により変わり、
この判断によっては後の計算結果の信頼度にも影響します。
選挙の出口調査や政党支持率予想、アンケートなどで母集団の「推測」を行っても、
調査機関や調査方法により推測と実体が違ってしまう事があるのはこの為です。
「標本(サンプル)」の取捨選択はプロの調査機関でも判断が難しい問題なのです。
「母平均μ」「標本平均x−」
「母集団」の平均が「母平均μ(ミュー)」、
「標本」の平均が「標本平均x−」です。
「母平均」と「標本平均x−」は同じ計算式で良い決まりです。
「母集団」の平均と「標本」の平均では値が近くなる為です。

これを踏まえて「分散」の説明をします。
「母分散σ2」と「標本分散s2」と「不偏分散u2」
「分散」とは各要素の「バラツキ度」の事です。
本来「分散」は「母分散σ2」を使用して計算を行うのが正しいのですが、
「統計」では常に「母集合」全ての値を取得できる状態では無い場合や、
全てを計算するコストを掛けられない事がよくあります。
そのような時は複数の「標本(サンプル)」要素から計算して、
「母分散σ2」を推測する必要が出てきます。
まず、式の違いを見て下さい。
・「母分散σ2」
全ての要素を元にして「分散」を計算する為の式です。

現実の状況に即した最良の「分散」の値が取得できます。

現実の状況に即した最良の「分散」の値が取得できます。
・「標本分散s2」
「sample variance、標本のバランス」のイニシャル「s」を使用。
「標本分散s2」は「母分散σ2」と同じ式です。

「標本となる要素数」が十分多ければ誤差は少ないのですが、
「標本となる要素数」が少なくなる程「母分散σ2」に比べて、
答えとなるバラツキ度の数値が小さく見積もられる特徴があります。

「標本となる要素数」が十分多ければ誤差は少ないのですが、
「標本となる要素数」が少なくなる程「母分散σ2」に比べて、
答えとなるバラツキ度の数値が小さく見積もられる特徴があります。
・「不偏分散u2」(標本不偏分散u2)
「unbiased variance、公平なバランス」のイニシャル「u」を使用。
「不偏分散u2」は「標本分散s2」に「−1」の「補正」が入ったものです。

以下のような書き方もできます

「標本となる要素数」が少なくても「標本分散s2」に比べて、
より「母分散σ2」に近い値が取得できます。

以下のような書き方もできます
「標本となる要素数」が少なくても「標本分散s2」に比べて、
より「母分散σ2」に近い値が取得できます。
・「分散V[X]」
「確率変数X」の分散「分散V[X]」については
「統計-基本3」以降の「確率と期待値」について解説する時に説明します。
「統計-基本3」以降の「確率と期待値」について解説する時に説明します。
「母分散」の「標本(サンプル)」である「標本分散s2」は、
「標本となる要素数」が少ないと「母分散σ2」より数値が小さくなります。
これを、より「母分散σ2」に近づける為に
分母に「−1」の「補正」を加えたのが「不偏分散u2」です。
ここからがややこしいのですが、
一部の書物やWebでは
「不偏分散u2」の式を「標本分散s2」として紹介や表記する事例をよく目にします。
厳密にはこの定義式の表記方法でも間違えではないのですが、
「補正」の入っていない「標本分散s2」
「補正」の入った「不偏分散u2」
は区別して理解しておいた方が後々混乱しにくいと思います。
この形で覚えておいた方が良いでしょう。
その上で混同使用される事があるという現状を知っておいて下さい。
また、
「標本分散s2」や「不偏分散u2」の式を「標本(サンプル)」として扱わないで、
最初から「母分散σ2」に見立てた前提で「分散σ2」と記述を行って
説明される事がよくあります。
これらを踏まえて「標準偏差」の説明をします。
「母標準偏差σ」と「標本標準偏差s」と「不偏標準偏差u」
「標準偏差」とは「√分散」の計算を行った「バラツキ度」の事です。
本来「標準偏差」は「母分散σ2」を使い「母標準偏差σ」を計算するのが正しいのですが、
それがままならない時は「標本分散s2」や「不偏分散u2」から「標準偏差」を推測します。
式の違いを見て下さい。
・「母標準偏差σ」
全ての要素を元にして「標準偏差」を計算する為の式です。

現実の状況に即した最良の「標準偏差」の値が取得出来ます。
現実の状況に即した最良の「標準偏差」の値が取得出来ます。
・「標本標準偏差s」(標本偏差s)
「sample variance、標本のバランス」のイニシャル「s」を使用。
「標本標準偏差s」は「母標準偏差σ」と同じ式です。

「標本となる要素数」が十分多ければ誤差は少なくなりますが、
「標本となる要素数」が少なくなる程「母標準偏差σ」に比べて、
答えとなるバラツキ度の数値が小さく見積もられる特徴があります。

「標本となる要素数」が十分多ければ誤差は少なくなりますが、
「標本となる要素数」が少なくなる程「母標準偏差σ」に比べて、
答えとなるバラツキ度の数値が小さく見積もられる特徴があります。
・「不偏標準偏差u」(不偏標本標準偏差u)
「unbiased variance、公平なバランス」のイニシャル「u」を使用。
「不偏標準偏差u」は「標本標準偏差s」に「−1」の「補正」が入ったものです。

以下のような書き方もできます

「標本となる要素数」が少なくても「標本標準偏差s」に比べて、
より「母標準偏差σ」に近い値が取得できます。

以下のような書き方もできます
「標本となる要素数」が少なくても「標本標準偏差s」に比べて、
より「母標準偏差σ」に近い値が取得できます。
「母標準偏差σ」「標本標準偏差s」「不偏標準偏差u」の違いは
「母分散σ2」「標本分散s2」「不偏分散u2」の違いに準じる形となり、
結果、以下のような事が言えます。
「母標準偏差σ」の「標本(サンプル)」である「標本標準偏差s」は
「標本となる要素数」が少ないと「母標準偏差σ」より数値が小さくなります。
これを、より「母標準偏差σ」に近づける為に
分母に「−1」の「補正」を加えたのが「不偏標準偏差u」です。
(「補正」とは分母の観測個数nから1を引く事を指します)
「分散」の時と同様に「標準偏差」でも以下の使われ方をする事があります。
「不偏標準偏差u」を「標本標準偏差s」として「補正」折り込み済みで
紹介や表記する事例がある。
「標本標準偏差s」や「不偏標準偏差u」の式を「母標準偏差σ」と見立てて
「標準偏差σ」として説明する事がある。
混乱しやすい部分なので気をつけて下さい。
「平均値(アベレージ)、中央値(メジアン)、最頻値(モード)」
「平均値(アベレージ)」「中央値(メジアン)」「最頻値(モード)」
・「平均値、算術平均」(アベレージ)
「全部の要素の数字を足してから要素の数で割ったもの」
が「平均値」です。「算術平均」とも言われます。
「{1, 2, 3, 4, 5, 6}」
から「平均値」を求める場合
「(1+2+3+4+5+6)/6 = 3.5」
よって、「平均値 = 3.5」
から「平均値」を求める場合
「(1+2+3+4+5+6)/6 = 3.5」
よって、「平均値 = 3.5」
・「中央値」(メジアン)
「昇順か降順に要素の数字を並べた時、中心に来る値」
が「中央値」です。
「{1, 2, 2, 3, 4, 5, 6}」
から「中央値」を求める場合「真ん中の3が中央値」となります。
よって、「中央値 = 3」
「{1, 2, 3, 3, 4, 5, 6, 7}」
のように「要素の数が偶数」の場合、
「真ん中の2つの要素を足して2で割った数が中央値」となります。
「(3+4)/2 = 3.5」
よって、「中央値 = 3.5」
から「中央値」を求める場合「真ん中の3が中央値」となります。
よって、「中央値 = 3」
「{1, 2, 3, 3, 4, 5, 6, 7}」
のように「要素の数が偶数」の場合、
「真ん中の2つの要素を足して2で割った数が中央値」となります。
「(3+4)/2 = 3.5」
よって、「中央値 = 3.5」
・「最頻値」(モード)
「一番出現回数の多い要素の数値」もしくは「一番出現回数の多い範囲」
が「最頻値」です。
「最頻値」
「{1, 2, 3, 3, 4, 5, 5, 5}」
から「最頻値」を求める場合「出現回数が一番多い5が最頻値」となります。
よって、「最頻値 = 5」
「最頻値が定まらない」
「{1, 2, 3, 4, 5, 6}」
のように「最頻値が定まらない」事があります。
よって、「最頻値 = 定まらない」
「二峰性により最頻値が定まらない」
「{1, 2, 2, 3, 4, 4, 5}」
「出現回数が一番多いのが2と4」と2カ所出現する事を
「二峰性(にほうせい)」と言います。
「最頻値が複数あり、定まらない」状態です。
よって、「最頻値 = 定まらない」
「多峰性により最頻値が定まらない」
「{1, 2, 2, 3, 4, 4, 5, 6, 6}」
「出現回数が一番多いのが2と4と6」と複数存在する事を
「多峰性(たほうせい)」と言います。
これも「最頻値が複数あり、定まらない」状態です。
よって、「最頻値 = 定まらない」
(「出現回数が一番多い所」が1カ所と定まる事は「単峰性」と言う。)
「最頻値が定まらない時の解決方法」
「最頻値」が「定まらない」場合は、
「特定の範囲で要素が何度が現れるか」で分けるとうまく行く事があります。
「{1, 3, 5, 11, 13, 24}」
↓範囲分け
「1〜10は3度、11〜20は2度、21〜30は1度」
よって、「最頻値 = 1〜10」
「{1, 2, 3, 3, 4, 5, 5, 5}」
から「最頻値」を求める場合「出現回数が一番多い5が最頻値」となります。
よって、「最頻値 = 5」
「最頻値が定まらない」
「{1, 2, 3, 4, 5, 6}」
のように「最頻値が定まらない」事があります。
よって、「最頻値 = 定まらない」
「二峰性により最頻値が定まらない」
「{1, 2, 2, 3, 4, 4, 5}」
「出現回数が一番多いのが2と4」と2カ所出現する事を
「二峰性(にほうせい)」と言います。
「最頻値が複数あり、定まらない」状態です。
よって、「最頻値 = 定まらない」
「多峰性により最頻値が定まらない」
「{1, 2, 2, 3, 4, 4, 5, 6, 6}」
「出現回数が一番多いのが2と4と6」と複数存在する事を
「多峰性(たほうせい)」と言います。
これも「最頻値が複数あり、定まらない」状態です。
よって、「最頻値 = 定まらない」
(「出現回数が一番多い所」が1カ所と定まる事は「単峰性」と言う。)
「最頻値が定まらない時の解決方法」
「最頻値」が「定まらない」場合は、
「特定の範囲で要素が何度が現れるか」で分けるとうまく行く事があります。
「{1, 3, 5, 11, 13, 24}」
↓範囲分け
「1〜10は3度、11〜20は2度、21〜30は1度」
よって、「最頻値 = 1〜10」
分布図による「平均値、中央値、最頻値」のパターン
分布図の形によって、
「平均値(アベレージ)」「中央値(メジアン)」「最頻値(モード)」に
大体以下の違いが出ます。
・中央が盛り上がった山型の分布図

「平均値、中央値、最頻値」が山の中心付近に集まる特性がある。
「正規分布」の理想的な形(ベル型)です。
・片側に盛り上がった山型の分布図

山の峰から「最頻値、中央値、平均値」の順に並びやすい特性がある。
C# 統計・微分積分・線形代数への道
次へ→http://1studying.blogspot.jp/2017/08/senkei-index.html#kuw05
他
以下のサイトを参考にしました。
標準正規確率表(σの確率表)
http://aoki2.si.gunma-u.ac.jp/lecture/Bunpu/normdist/hyojunka.html#tab1
偏差値とは何かをおさらい!意味・求め方・正規分布との関係性のまとめ
https://atarimae.biz/archives/9109
分散の求め方と公式。その有用性について
https://atarimae.biz/archives/8782
不偏標準偏差の出し方
https://detail.chiebukuro.yahoo.co.jp/qa/question_detail/q11148040646
統計学における分散と不偏分散 例題でわかりやすく解説
https://to-kei.net/basic/glossary/variance/
不偏標本分散の意味とn-1で割ることの証明
https://mathtrain.jp/huhenbunsan
勘違いしやすい統計用語の定義。標本の大きさと標本数・母数・不偏標準偏差など
https://atarimae.biz/archives/10319
統計のウソ
http://ronri2.web.fc2.com/tokei.html
http://ronri2.web.fc2.com/tokei04.html
「12-5. 確率変数の分散」
https://bellcurve.jp/statistics/course/6716.html
さまざまな確率分布
http://www.biwako.shiga-u.ac.jp/sensei/mnaka/ut/statdist.html
統計web:統計学の時間
https://bellcurve.jp/statistics/course/
数学記号の表
https://ja.wikipedia.org/wiki/%E6%95%B0%E5%AD%A6%E8%A8%98%E5%8F%B7%E3%81%AE%E8%A1%A8
数式記号の読み方・表し方
http://izumi-math.jp/sanae/report/suusiki/suusiki.htm