C# 統計・微分積分・線形代数への道
目次→http://1studying.blogspot.jp/2017/08/senkei-index.html#kuw03
「統計の基本」
メモっておく。
ここでは、
「×」を「*」
「÷」や「分数」を「/」
で表現します。
Σとは…
Σは「和の記号」と呼ばれています。
Σは総和(合計)を表します。
合計は英語で「Summation」、
このイニシャルの「S」はギリシャ文字で「Σ」を指します。
Σは、
繰り返し数値を足して合計を求める時に使用し、

のように書きます。
これは、以下の計算が繰り返される事を意味します。
「Σ」の右横の「a」には「計算式」が入ります。
「Σ」の計算結果(合計)を「resultSum」として考えます。
「変数i」が「n」の値になるまで「計算式a」を繰り返す形となります。
1)「resultSum」に「0」を初期値として設定。
2)「変数i」に「1」を初期値として設定。
3)「計算式a」の計算結果を「resultSum」へ加算。
4)「変数i」が「n」の値なら終了。
そうでないなら「変数i」を「+1」して「3)」から繰り返し。
終了時の「resultSum」の値が「答え」となります。
(「変数i」は「添え字i」などと言われる事もあります。
別に「i」以外の「kやx」などの変数でも構いません)
計算例1

変数「i = 1」でスタート(繰り返し毎に「+1」)
計算式「2」を「変数i」が「3」になるまで「3回繰り返し」足しています。
計算例2

変数「i = 3」でスタート(繰り返し毎に「+1」)。
計算式「i+2」を「変数i」が「6」になるまで「4回繰り返し」足しています。
Σの書き方
下図の「Σ」の「計算式(i+5)」は「計算式ai」と省略して表記出来ます。
その場合「計算式ai」の中身が「(i+5)」である事の明示が必要です。

この式の、
「計算式(i+5)」の部分を「ai」と表記する事により、
「a1」「a2」「a3」のような書き方が可能です。

この書き方の便利な所は、
『「ai = (i+5)」です』
『「計算式ai」は「(i+5)」です』
のように「ai」の中身は「 (i+5)」と明示する事により、
「a1」は「(1+5)」を指します
「a2」は「(2+5)」を指します
「a3」は「(3+5)」を指します
と「ai」の「変数i」に入る数値に従った「(i+5)」の式の結果を得る事ができます。
公式ではこの「ai」を使用した書き方の事を、

のように表現しています。
階和の公式
「1+2+3+4+5+6+…+?」
のような「1」から決まった数まで順に足していく式の事を「階和」と言います。
「階和」で繰り返し足す回数を「n」で表した「階和の公式」が

です。
当然「等式=」左側と右側で必ず同じ答えとなります。
「左側の式」「Σ」を使って計算すると…
「Σ」上部の「n」を「4」とした時
「1+2+3+4 = 10」
となります。
「右側の式」を使って計算すると…
「(n(n+1))/ 2」の「n」を「4」とした時
「(4*(4+1))/ 2 = 20/2 = 10」
となります。
「階和の公式」を使うと「階和」の計算がとても便利になります。
例えば「1〜100」までの「階和」を計算する場合などは、
「左側の式」「Σ」を使って計算すると
「1+2+3+4+…100 = ?」
と式を書くのも計算するのも大変そうなのが、
「右側の式」を使って計算すれば
「(100*(100+1))/ 2 = ?」
と簡単な式で書けるようになります。
この「階和の公式」を利用して、
「Σ」の「計算式」を「計算式(i+5)」とした場合、
「計算式(i+5)」を「+5n」として「等式=」右側に記述する事ができます。

この式をつかえば、
「n」が幾つであっても素早く計算する事ができます。
例えば「n = 3」した場合、

のような形で
「(1+5)+(2+5)+(3+5)= ?」
を計算する事ができました。
Πとは…
Πは「積の記号」と呼ばれています。
数学では「Πパイ」と呼ばず「全ての積」と呼ばれています。
Πは総乗、総積を表します。
積は英語で「Product」、
このイニシャルの「P」はギリシャ文字で「Π」を指します。
Πは、
繰り返し数値を掛けて合計を求める時に使用し、

のように書きます。
これは、以下の計算が繰り返される事を意味します。
「Π」の右横の「a」には「計算式」が入ります。
「Π」の計算結果(総乗)を「resultProduct」として考えます。
「変数i」が「n」の値になるまで「計算式a」を繰り返す形となります。
1)「resultProduct」に「1」を初期値として設定。
2)「変数i」に「1」を初期値として設定。
3)「計算式a」の計算結果を「resultProduct」の値と掛け算を行い、
その結果を改めて「resultProduct」へ格納。
4)「変数i」が「n」の値なら終了。
そうでないなら「変数i」を「+1」して「3)」から繰り返し。
終了時「resultProduct」の値が「答え」となります。
(「変数i」は「添え字i」などと言われる事もあります。
別に「i」以外の「kやx」などの変数でも構いません)
計算例1

変数「i = 1」でスタート(繰り返し毎に「+1」)
計算式「2」を「変数i」が「3」になるまで「3回繰り返し」掛けています。
計算例2

変数「i = 3」でスタート(繰り返し毎に「+1」)。
計算式「i+2」を「変数i」が「6」になるまで「4回繰り返し」掛けています。
Πの書き方
「Σ」と同じように、
「計算式」を「計算式ai」と省略する事により、

と「Π」の式を表現できます。
例えば、
「計算式ai」は「ai = (i+5)」ですと明示して、
「n = 3」です
とした場合を「Π」の式にすると

のような書き方となります。
Σで平均を計算する公式

が「平均(average)」を計算する公式となります。

のようにも記述する事ができます。
これだけだと分かりにくいので、
計算例を書きます。
「平均(average)」計算例
「計算式ai」の結果として以下の4つの数値があったとします。
「a1=2」「a2=4」「a3=8」「a4=12」
この4つの数値の「平均(average)」を調べる為に
「n = 4」
として計算を行ってみます。

よって、
「平均(average)」は「6.5」
となりました。
これを
C#のプログラムで書いた場合以下のようになります。
「偏差」って何?
「平均(average)」からの距離を「偏差」と言います。
「ai」がそれぞれ
「a1=2」「a2=4」「a3=8」「a4=12」
として4つの「ai」の
「平均(average) = 6.5」
とした場合

のようになり、
それぞれの「偏差」は
「a1偏差=-4.5」「a2偏差=-2.5」「a3偏差=1.5」「a4偏差=5.5」
という事になります。
Σで「平均偏差」を計算する公式
「平均偏差」は「偏差の絶対値」(マイナスの取れた偏差)の「平均」です。
(「平均偏差」は「平均(average)」からの距離の平均です。)

が「平均偏差」の公式となります。

のように式を変形させる事が出来ます。
これだけだと分かりにくいので、
「平均偏差」の計算例を書きます。
「平均偏差」計算例
「ai」がそれぞれ
「a1=2」「a2=4」「a3=8」「a4=12」
として、
まずは「平均(average)」を計算します。

これにより
「平均(average)」が「6.5」
と分かりました。
次に、
「平均(average) = 6.5」を使って
「平均偏差」を計算します。

よって、
「平均偏差」が「3.5」
となりました。
つまり、
「平均からの各要素のバラツキ度」の「平均」が「平均偏差」
なのです。
但し「平均偏差」は実はあまり使われません。
「標準偏差σ」と「分散」
が主に「バラツキ度」を計る数値として使用されます。
これらについては後で説明します。
C#でプログラムで書いた場合以下のようになります。
補足(平均記号の書き方)
今回はイメージしやすくする為に

としました。
本来は要素となるべき記号は「ai」ではなく「xi」を使います。
「xの頭に横棒」を付けると「xの標本平均」(x配列の平均)を指すので、

とするのが主流です。
例えば「偏差」を表す場合は

のように表します。
「母平均μ(母集団の平均)」とは
「母平均μ」は、
「全て要素から作った配列」から作られた「平均」という意味です。
「母平均μ」を求める公式

「標本平均」とは
「標本平均x−」とは
「全要素から標本となる要素を抽出して並べた配列」から作られた「平均」という意味です。
「標本平均x−」を求める公式

「母平均μ(母集団の平均)」と「標本平均」
公式を見比べると、両方とも計算方法が同じである事に気付きます。
平均を求める計算方法は同じですが、
「全要素の平均」なのか、一部の「標本からの平均」なのかで意味合いが変わります。
意味の違いに注意して下さい。

「標準偏差σ」と「分散」とは何か…
「標準偏差σ」や「分散」とは、
配列の「平均値」からどれ位近付いたり離れたりして
「配列内の各要素個々の値」が分布しているか、
分布によるバラツキの「バラツキ度」を数値化した物です。
「バラツキ度」の数値が大きいと、分布にバラツキが出て
配列内の各要素個々の数値が平均値周辺に集まりにくくなります。
「バラツキ度」の数値が小さいと、分布にバラツキが無くなり
配列内の各要素個々の数値が平均値周辺に集まります。
「バラツキ度」の種類は
・「標準偏差σ」
→「分散」に「√」ルートを付けた値(「正規分布」で使用)
・「分散」
→「平均(average)」との「差(偏差の距離)」を2乗した物の平均
の2種類があり、
普段は(「正規分布」で使用する為)「標準偏差σ」を使います。
「標準偏差σ」と「分散」の公式
「σ(小文字のシグマ)」は「標準偏差」を示しています。
「標準偏差σ」の公式は

となります。ここから

という公式に倣って
「分散」に付いている「√ルート」を外せば、
↓「分散」の公式となります。

「標準偏差σ」や「分散」の公式では、
「偏差」を公式の中で「絶対値」化して使用します。

のように「偏差」を「2乗」する事で、
「絶対値」(マイナスの取れた2乗)を得て公式内で使用しています。
上記「標準偏差σ」の公式は、
「√」を「σ2」に記述する事で

のように書く事もできます。
これら「標準偏差σ」や「分散」の公式が
具体的にどのように使われるのかを説明します。
「正規分布」とは…
「標準偏差σ」や「分散」は「正規分布」で使用する事が多い為、
「正規分布」について説明しておきます。
「正規分布」のグラフとは、
「縦軸が要素数」「横軸が平均を中心とした要素の数値」です。

「正規分布」のグラフを見ると、
「平均周辺(中心周辺)の数値は
→ 要素の数が多いので、試行結果の出現率が高い」
「平均周辺(中心周辺)から離れた数値は
→ 要素の数が少ないので、試行結果の出現率が低い」
事が分かります。
このバラツキによる「出現率」を「68-95-99.7ルール」と呼びます。
「各要素」の「正規分布」グラフ内での「出現率」が、
「±σ区間」内に収まる確率が「約68.2%」(34.13%*2)
「±2σ区間」内に収まる確率が「約95.4%」(47.72%*2)
「±3σ区間」内に収まる確率が「約99.7%」(49.87%*2)
となる為です。
「±3σ区間」で「99.7%」と殆どの要素が収まる為、
「3σ」が指標として使われる事が多いようです。
では、「正規分布」を使用して実際の計算を行います。
「計算例」を確認して下さい。
計算例(「標準偏差σ」と「分散」と「正規分布」)
配列内各要素の数値がそれぞれ、
「x1=2」「x2=4」「x3=8」「x4=12」
の場合の「平均(average)」を計算します。

よって、「平均(average)」が「6.5」と分かりました。
次に「分散」を計算します。

よって、「分散」が「14.75」と分かりました。
次に「標準偏差σ」を計算します。

よって、「標準偏差σ」が「3.840572874」と分かりました。
それぞれの結果、
「平均(average)」が「6.5」
「分散」が「14.75」
「標準偏差σ」が「3.840572874」
を「正規分布」に照らし合わせると以下のイメージとなります。

6.5 ±σ → 全体の約68.2%
6.5 ±2σ → 全体の約95.4%
6.5 ±3σ → 全体の約99.7%
「標準偏差σ = 3.840572874」をあてはめると、
「6.5 ± 3.840572874 → 全体の約68.2%」
「6.5 ±(2*3.840572874) → 全体の約95.4%」
「6.5 ±(3*3.840572874) → 全体の約99.7%」
となります。
つまり複数回の試行を行った結果、
「x1=2」「x2=4」「x3=8」「x4=12」だった場合、
試行の平均が「6.5」となり
「約68%」の確率で「6.5 ±3.840572874範囲内」の数値です。
「約95%」の確率で「6.5 ±7.681145748範囲内」の数値です。
「約99.7%」の確率で「6.5 ±11.52171862範囲内」の数値です。
と言う事が出来ます。
「約68%」の確率で「6.5 ±3.840572874範囲内」の数値と予測しているので、
次の1回試行を行ったとき、
約68%の確率で「(6.5−約3.84)〜(6.5+3.84)の範囲内」に要素が入るだろう
と予測される。
とも言えます。
言い換えると、
これは例えるなら、
中心目指してボールを落とした場合
「統計的予測」については後々もう少し掘り下げる予定です。
この計算例の「正規分布」以降の結果には以下の注意が必要です。
もっと沢山の「標本(サンプル)」を用意し計算すればより精度は高くなります。
但しその際、
「各要素の分布状況」が「正規分布」の形に近い必要がある事を忘れないで下さい。
「各要素の分布」を「正規分布」(ベル型)の形状のような分析出来る状態にする為には
試行回数を増やすのがスタンダードな方法ですが、
他にも色々な工夫の方法が存在します。
この課題はここで一旦置いておき、
「他の工夫の方法(中心極限定理、Box-Cox変換、パラメトリック、ノンパラメトリック)」
については後々に学習できたらと思います。
C# 統計・微分積分・線形代数への道
次へ→http://1studying.blogspot.jp/2017/08/senkei-index.html#kuw04
以下のサイトを参考にしました。
Wikipedia:総和
https://ja.wikipedia.org/wiki/%E7%B7%8F%E5%92%8C
Wikipedia:総乗
https://ja.wikipedia.org/wiki/%E7%B7%8F%E4%B9%97
これでわかる!数列のシグマΣの計算方法を徹底解説
http://sakusaku-study.com/sigma
5分で分かる!総和記号「Σ(シグマ)」の計算方法
https://blog.apar.jp/data-analysis/4407/
和と積の記号:ΣとΠ
http://mcn-www.jwu.ac.jp/~yokamoto/ccc/math/sgmpi/
【統計学】初めての「標準偏差」(統計学に挫折しないために)
http://qiita.com/kenmatsu4/items/e6c6acb289c02609e619
wiki:標準偏差
https://ja.wikipedia.org/wiki/%E6%A8%99%E6%BA%96%E5%81%8F%E5%B7%AE
wiki:正規分布
https://ja.wikipedia.org/wiki/%E6%AD%A3%E8%A6%8F%E5%88%86%E5%B8%83
3σとは何ですか?
https://detail.chiebukuro.yahoo.co.jp/qa/question_detail/q1434162719
さまざまな確率分布
http://www.biwako.shiga-u.ac.jp/sensei/mnaka/ut/statdist.html
実際の事象におけるデータの分布と確率分布、一部のデータから全体を推測する考え方
https://www.marketechlabo.com/probability-inferential-statistics/
統計web:統計学の時間
https://bellcurve.jp/statistics/course/
数学記号の表
https://ja.wikipedia.org/wiki/%E6%95%B0%E5%AD%A6%E8%A8%98%E5%8F%B7%E3%81%AE%E8%A1%A8
数式記号の読み方・表し方
http://izumi-math.jp/sanae/report/suusiki/suusiki.htm
目次→http://1studying.blogspot.jp/2017/08/senkei-index.html#kuw03
「統計の基本」
メモっておく。
ここでは、
「×」を「*」
「÷」や「分数」を「/」
で表現します。
和の記号Σ(シグマ)総和
Σとは…
Σは「和の記号」と呼ばれています。
Σは総和(合計)を表します。
合計は英語で「Summation」、
このイニシャルの「S」はギリシャ文字で「Σ」を指します。
Σは、
繰り返し数値を足して合計を求める時に使用し、

のように書きます。
これは、以下の計算が繰り返される事を意味します。
「Σ」の右横の「a」には「計算式」が入ります。
「Σ」の計算結果(合計)を「resultSum」として考えます。
「変数i」が「n」の値になるまで「計算式a」を繰り返す形となります。
1)「resultSum」に「0」を初期値として設定。
2)「変数i」に「1」を初期値として設定。
3)「計算式a」の計算結果を「resultSum」へ加算。
4)「変数i」が「n」の値なら終了。
そうでないなら「変数i」を「+1」して「3)」から繰り返し。
終了時の「resultSum」の値が「答え」となります。
(「変数i」は「添え字i」などと言われる事もあります。
別に「i」以外の「kやx」などの変数でも構いません)
計算例1

変数「i = 1」でスタート(繰り返し毎に「+1」)
計算式「2」を「変数i」が「3」になるまで「3回繰り返し」足しています。
var resultSum = 0; //「resultSum」に計算結果が入ります
var n = 3;
for (var i = 1; i <= n; i++){
resultSum += 2; //2を加算
}
よって、「resultSum=6」となります。計算例2

変数「i = 3」でスタート(繰り返し毎に「+1」)。
計算式「i+2」を「変数i」が「6」になるまで「4回繰り返し」足しています。
var resultSum = 0; //「resultSum」に計算結果が入ります
var n = 6;
for (var i = 3; i <= n; i++)
{
resultSum += (i + 2); //(i+2)を加算
}
よって、「resultSum=26」となります。Σの書き方
下図の「Σ」の「計算式(i+5)」は「計算式ai」と省略して表記出来ます。
その場合「計算式ai」の中身が「(i+5)」である事の明示が必要です。

この式の、
「計算式(i+5)」の部分を「ai」と表記する事により、
「a1」「a2」「a3」のような書き方が可能です。

この書き方の便利な所は、
『「ai = (i+5)」です』
『「計算式ai」は「(i+5)」です』
のように「ai」の中身は「 (i+5)」と明示する事により、
「a1」は「(1+5)」を指します
「a2」は「(2+5)」を指します
「a3」は「(3+5)」を指します
と「ai」の「変数i」に入る数値に従った「(i+5)」の式の結果を得る事ができます。
公式ではこの「ai」を使用した書き方の事を、

のように表現しています。
階和の公式
「1+2+3+4+5+6+…+?」
のような「1」から決まった数まで順に足していく式の事を「階和」と言います。
「階和」で繰り返し足す回数を「n」で表した「階和の公式」が

です。
当然「等式=」左側と右側で必ず同じ答えとなります。
「左側の式」「Σ」を使って計算すると…
「Σ」上部の「n」を「4」とした時
「1+2+3+4 = 10」
となります。
「右側の式」を使って計算すると…
「(n(n+1))/ 2」の「n」を「4」とした時
「(4*(4+1))/ 2 = 20/2 = 10」
となります。
「階和の公式」を使うと「階和」の計算がとても便利になります。
例えば「1〜100」までの「階和」を計算する場合などは、
「左側の式」「Σ」を使って計算すると
「1+2+3+4+…100 = ?」
と式を書くのも計算するのも大変そうなのが、
「右側の式」を使って計算すれば
「(100*(100+1))/ 2 = ?」
と簡単な式で書けるようになります。
この「階和の公式」を利用して、
「Σ」の「計算式」を「計算式(i+5)」とした場合、
「計算式(i+5)」を「+5n」として「等式=」右側に記述する事ができます。
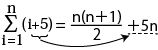
この式をつかえば、
「n」が幾つであっても素早く計算する事ができます。
例えば「n = 3」した場合、

のような形で
「(1+5)+(2+5)+(3+5)= ?」
を計算する事ができました。
Π(大文字のパイ)総乗、総積
Πとは…
Πは「積の記号」と呼ばれています。
数学では「Πパイ」と呼ばず「全ての積」と呼ばれています。
Πは総乗、総積を表します。
積は英語で「Product」、
このイニシャルの「P」はギリシャ文字で「Π」を指します。
Πは、
繰り返し数値を掛けて合計を求める時に使用し、

のように書きます。
これは、以下の計算が繰り返される事を意味します。
「Π」の右横の「a」には「計算式」が入ります。
「Π」の計算結果(総乗)を「resultProduct」として考えます。
「変数i」が「n」の値になるまで「計算式a」を繰り返す形となります。
1)「resultProduct」に「1」を初期値として設定。
2)「変数i」に「1」を初期値として設定。
3)「計算式a」の計算結果を「resultProduct」の値と掛け算を行い、
その結果を改めて「resultProduct」へ格納。
4)「変数i」が「n」の値なら終了。
そうでないなら「変数i」を「+1」して「3)」から繰り返し。
終了時「resultProduct」の値が「答え」となります。
(「変数i」は「添え字i」などと言われる事もあります。
別に「i」以外の「kやx」などの変数でも構いません)
計算例1

変数「i = 1」でスタート(繰り返し毎に「+1」)
計算式「2」を「変数i」が「3」になるまで「3回繰り返し」掛けています。
var resultProduct = 1; //「resultProduct」に計算結果が入ります
var n = 3;
for (var i = 1; i <= n; i++)
{
resultProduct *= 2; //2を掛ける
}
よって、「resultSum=8」となります。計算例2
変数「i = 3」でスタート(繰り返し毎に「+1」)。
計算式「i+2」を「変数i」が「6」になるまで「4回繰り返し」掛けています。
var resultProduct = 1; //「resultProduct」に計算結果が入ります
var n = 6;
for (var i = 3; i <= n; i++)
{
resultProduct *= (i + 2); //(i+2)を掛ける
}
よって、「resultSum=1680」となります。Πの書き方
「Σ」と同じように、
「計算式」を「計算式ai」と省略する事により、

と「Π」の式を表現できます。
例えば、
「計算式ai」は「ai = (i+5)」ですと明示して、
「n = 3」です
とした場合を「Π」の式にすると

のような書き方となります。
Σ(シグマ)から「平均」と「平均偏差」の計算方法
Σで平均を計算する公式

が「平均(average)」を計算する公式となります。

のようにも記述する事ができます。
これだけだと分かりにくいので、
計算例を書きます。
「平均(average)」計算例
「計算式ai」の結果として以下の4つの数値があったとします。
「a1=2」「a2=4」「a3=8」「a4=12」
この4つの数値の「平均(average)」を調べる為に
「n = 4」
として計算を行ってみます。

よって、
「平均(average)」は「6.5」
となりました。
これを
C#のプログラムで書いた場合以下のようになります。
double average = 0; //「average」に計算結果である平均が入ります
double sum = 0; //「sum」には合計値(総和)が入ります
var a = new double[] { 2, 4, 8, 12 };
var n = a.Length; //「a」の数
for (var i = 1; i <= n; i++){
sum += a[(i - 1)];//合計値(総和)を計算
}
average = sum / n; //「平均(average)」を計算
↓実はもっと簡単に書けます。 var a = new double[] { 2, 4, 8, 12 };
MessageBox.Show(a.Average().ToString()); //「平均(average)」を表示
「偏差」って何?
「平均(average)」からの距離を「偏差」と言います。
「ai」がそれぞれ
「a1=2」「a2=4」「a3=8」「a4=12」
として4つの「ai」の
「平均(average) = 6.5」
とした場合

のようになり、
それぞれの「偏差」は
「a1偏差=-4.5」「a2偏差=-2.5」「a3偏差=1.5」「a4偏差=5.5」
という事になります。
Σで「平均偏差」を計算する公式
「平均偏差」は「偏差の絶対値」(マイナスの取れた偏差)の「平均」です。
(「平均偏差」は「平均(average)」からの距離の平均です。)

が「平均偏差」の公式となります。

のように式を変形させる事が出来ます。
これだけだと分かりにくいので、
「平均偏差」の計算例を書きます。
「平均偏差」計算例
「ai」がそれぞれ
「a1=2」「a2=4」「a3=8」「a4=12」
として、
まずは「平均(average)」を計算します。

これにより
「平均(average)」が「6.5」
と分かりました。
次に、
「平均(average) = 6.5」を使って
「平均偏差」を計算します。
よって、
「平均偏差」が「3.5」
となりました。
つまり、
「平均からの各要素のバラツキ度」の「平均」が「平均偏差」
なのです。
但し「平均偏差」は実はあまり使われません。
「標準偏差σ」と「分散」
が主に「バラツキ度」を計る数値として使用されます。
これらについては後で説明します。
C#でプログラムで書いた場合以下のようになります。
double result = 0; //「result」に計算結果である「平均偏差」が入ります
double total = 0; //「偏差の絶対値」の合計が入ります
var a = new double[] { 2, 4, 8, 12 };
double average = a.Average(); //「平均(average)」の「6.5」が格納される
int n = a.Length; //「a」の数
for(int i=1; i <= n; i++)
{
total += Math.Abs(a[(i - 1)] - average);//「偏差の絶対値」の合計を計算
}
result = total / n;
MessageBox.Show(result.ToString()); //→「3.5」と表示
補足(平均記号の書き方)
今回はイメージしやすくする為に

としました。
本来は要素となるべき記号は「ai」ではなく「xi」を使います。
「xの頭に横棒」を付けると「xの標本平均」(x配列の平均)を指すので、

とするのが主流です。
例えば「偏差」を表す場合は

のように表します。
「母平均(母集団の平均)μ(ミュー)」と「標本平均x−」
「母平均μ(母集団の平均)」とは
「母平均μ」は、
「全て要素から作った配列」から作られた「平均」という意味です。
「母平均μ」を求める公式

「標本平均」とは
「標本平均x−」とは
「全要素から標本となる要素を抽出して並べた配列」から作られた「平均」という意味です。
「標本平均x−」を求める公式

「母平均μ(母集団の平均)」と「標本平均」
公式を見比べると、両方とも計算方法が同じである事に気付きます。
平均を求める計算方法は同じですが、
「全要素の平均」なのか、一部の「標本からの平均」なのかで意味合いが変わります。
意味の違いに注意して下さい。

「標準偏差σ(小文字のシグマ)、分散、正規分布」
「標準偏差σ」と「分散」とは何か…
「標準偏差σ」や「分散」とは、
配列の「平均値」からどれ位近付いたり離れたりして
「配列内の各要素個々の値」が分布しているか、
分布によるバラツキの「バラツキ度」を数値化した物です。
「バラツキ度」の数値が大きいと、分布にバラツキが出て
配列内の各要素個々の数値が平均値周辺に集まりにくくなります。
「バラツキ度」の数値が小さいと、分布にバラツキが無くなり
配列内の各要素個々の数値が平均値周辺に集まります。
「バラツキ度」の種類は
・「標準偏差σ」
→「分散」に「√」ルートを付けた値(「正規分布」で使用)
・「分散」
→「平均(average)」との「差(偏差の距離)」を2乗した物の平均
の2種類があり、
普段は(「正規分布」で使用する為)「標準偏差σ」を使います。
「標準偏差σ」と「分散」の公式
「σ(小文字のシグマ)」は「標準偏差」を示しています。
「標準偏差σ」の公式は

となります。ここから

という公式に倣って
「分散」に付いている「√ルート」を外せば、
↓「分散」の公式となります。

「標準偏差σ」や「分散」の公式では、
「偏差」を公式の中で「絶対値」化して使用します。

のように「偏差」を「2乗」する事で、
「絶対値」(マイナスの取れた2乗)を得て公式内で使用しています。
上記「標準偏差σ」の公式は、
「√」を「σ2」に記述する事で

のように書く事もできます。
これら「標準偏差σ」や「分散」の公式が
具体的にどのように使われるのかを説明します。
「正規分布」とは…
「標準偏差σ」や「分散」は「正規分布」で使用する事が多い為、
「正規分布」について説明しておきます。
「正規分布」のグラフとは、
例えば何かを複数回試行した結果を各要素の数値として記録して、
全要素の数値の「平均」を計算をします。
(例えば一人の人が目隠しして数千回
的の中心へ向けてボールを落とした場合、
中心からずれて落ちた距離の平均がその人の「実力距離」)
この試行回数が多い時、
「平均」付近の数値範囲に「要素数(記録数)」が一番多く集まり
「平均」から離れるほど「要素数(記録数)」が少ない
ちょうど「ベル型(正規分布型)」のグラフ図になる事がよくあります。
(「実力距離(平均)」付近より離れて落ちる球と近くに落ちる球で
記録に「バラツキ」が出るが「平均付近」に落ちる球が最も多くなる)
このような結果の形は「自然界」でよく起こり、
グラフ内のどの数値範囲に「要素数」が何%集まるかの「分布」状況が
ある程度パターンになるため、統計に利用する事ができます。
そのパターンをグラフ化した物が「正規分布」です。
「正規分布」は以下のグラフ図が基本となります。全要素の数値の「平均」を計算をします。
(例えば一人の人が目隠しして数千回
的の中心へ向けてボールを落とした場合、
中心からずれて落ちた距離の平均がその人の「実力距離」)
この試行回数が多い時、
「平均」付近の数値範囲に「要素数(記録数)」が一番多く集まり
「平均」から離れるほど「要素数(記録数)」が少ない
ちょうど「ベル型(正規分布型)」のグラフ図になる事がよくあります。
(「実力距離(平均)」付近より離れて落ちる球と近くに落ちる球で
記録に「バラツキ」が出るが「平均付近」に落ちる球が最も多くなる)
このような結果の形は「自然界」でよく起こり、
グラフ内のどの数値範囲に「要素数」が何%集まるかの「分布」状況が
ある程度パターンになるため、統計に利用する事ができます。
そのパターンをグラフ化した物が「正規分布」です。
「縦軸が要素数」「横軸が平均を中心とした要素の数値」です。

「正規分布」のグラフを見ると、
「平均周辺(中心周辺)の数値は
→ 要素の数が多いので、試行結果の出現率が高い」
「平均周辺(中心周辺)から離れた数値は
→ 要素の数が少ないので、試行結果の出現率が低い」
事が分かります。
このバラツキによる「出現率」を「68-95-99.7ルール」と呼びます。
「各要素」の「正規分布」グラフ内での「出現率」が、
「±σ区間」内に収まる確率が「約68.2%」(34.13%*2)
「±2σ区間」内に収まる確率が「約95.4%」(47.72%*2)
「±3σ区間」内に収まる確率が「約99.7%」(49.87%*2)
となる為です。
「±3σ区間」で「99.7%」と殆どの要素が収まる為、
「3σ」が指標として使われる事が多いようです。
では、「正規分布」を使用して実際の計算を行います。
「計算例」を確認して下さい。
計算例(「標準偏差σ」と「分散」と「正規分布」)
配列内各要素の数値がそれぞれ、
「x1=2」「x2=4」「x3=8」「x4=12」
の場合の「平均(average)」を計算します。
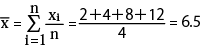
よって、「平均(average)」が「6.5」と分かりました。
次に「分散」を計算します。
よって、「分散」が「14.75」と分かりました。
次に「標準偏差σ」を計算します。

よって、「標準偏差σ」が「3.840572874」と分かりました。
それぞれの結果、
「平均(average)」が「6.5」
「分散」が「14.75」
「標準偏差σ」が「3.840572874」
を「正規分布」に照らし合わせると以下のイメージとなります。

6.5 ±σ → 全体の約68.2%
6.5 ±2σ → 全体の約95.4%
6.5 ±3σ → 全体の約99.7%
「標準偏差σ = 3.840572874」をあてはめると、
「6.5 ± 3.840572874 → 全体の約68.2%」
「6.5 ±(2*3.840572874) → 全体の約95.4%」
「6.5 ±(3*3.840572874) → 全体の約99.7%」
となります。
つまり複数回の試行を行った結果、
「x1=2」「x2=4」「x3=8」「x4=12」だった場合、
試行の平均が「6.5」となり
「約68%」の確率で「6.5 ±3.840572874範囲内」の数値です。
「約95%」の確率で「6.5 ±7.681145748範囲内」の数値です。
「約99.7%」の確率で「6.5 ±11.52171862範囲内」の数値です。
と言う事が出来ます。
「約68%」の確率で「6.5 ±3.840572874範囲内」の数値と予測しているので、
次の1回試行を行ったとき、
約68%の確率で「(6.5−約3.84)〜(6.5+3.84)の範囲内」に要素が入るだろう
と予測される。
とも言えます。
言い換えると、
ここから「標本(サンプル)」(試行)の数を1回増やしたとき、
「平均±標準偏差σ」の範囲内には、
全体の「約68%」の「要素」が含まれる形と予想でき、
「標本(サンプル)」(試行)の数が無限に近付くほど
この予測の精度は上がる
という事です。「平均±標準偏差σ」の範囲内には、
全体の「約68%」の「要素」が含まれる形と予想でき、
「標本(サンプル)」(試行)の数が無限に近付くほど
この予測の精度は上がる
これは例えるなら、
中心目指してボールを落とした場合
平均が「6.5メートル」の位値に落ちる事と、
落ちたボールの「バラツキ度」から見て、
「(6.5m−約3.84m)〜(6.5m+3.84m)の距離の範囲内」に
「約68%」のボールが落ちたので、
次の試行でこの範囲ボールが落ちる確率も「約68%」です。

と統計的に予測できる事になります。落ちたボールの「バラツキ度」から見て、
「(6.5m−約3.84m)〜(6.5m+3.84m)の距離の範囲内」に
「約68%」のボールが落ちたので、
次の試行でこの範囲ボールが落ちる確率も「約68%」です。
「統計的予測」については後々もう少し掘り下げる予定です。
この計算例の「正規分布」以降の結果には以下の注意が必要です。
ここでは説明の為たった4つの要素で計算例を示していますが、
試行回数が極端に少ないのでグラフ化しても「正規分布」に見えません。

その為、実際は計算結果の信頼性が著しく低くなり予測の意味をなしません。
本来は試行回数を増やし、グラフを「正規分布」の形状に近づける必要があります。

今回は「標本(サンプル)」を4つでの計算でしたが、試行回数が極端に少ないのでグラフ化しても「正規分布」に見えません。

その為、実際は計算結果の信頼性が著しく低くなり予測の意味をなしません。
本来は試行回数を増やし、グラフを「正規分布」の形状に近づける必要があります。

もっと沢山の「標本(サンプル)」を用意し計算すればより精度は高くなります。
但しその際、
「各要素の分布状況」が「正規分布」の形に近い必要がある事を忘れないで下さい。
「各要素の分布」を「正規分布」(ベル型)の形状のような分析出来る状態にする為には
試行回数を増やすのがスタンダードな方法ですが、
他にも色々な工夫の方法が存在します。
この課題はここで一旦置いておき、
「他の工夫の方法(中心極限定理、Box-Cox変換、パラメトリック、ノンパラメトリック)」
については後々に学習できたらと思います。
C# 統計・微分積分・線形代数への道
次へ→http://1studying.blogspot.jp/2017/08/senkei-index.html#kuw04
他
以下のサイトを参考にしました。
Wikipedia:総和
https://ja.wikipedia.org/wiki/%E7%B7%8F%E5%92%8C
Wikipedia:総乗
https://ja.wikipedia.org/wiki/%E7%B7%8F%E4%B9%97
これでわかる!数列のシグマΣの計算方法を徹底解説
http://sakusaku-study.com/sigma
5分で分かる!総和記号「Σ(シグマ)」の計算方法
https://blog.apar.jp/data-analysis/4407/
和と積の記号:ΣとΠ
http://mcn-www.jwu.ac.jp/~yokamoto/ccc/math/sgmpi/
【統計学】初めての「標準偏差」(統計学に挫折しないために)
http://qiita.com/kenmatsu4/items/e6c6acb289c02609e619
wiki:標準偏差
https://ja.wikipedia.org/wiki/%E6%A8%99%E6%BA%96%E5%81%8F%E5%B7%AE
wiki:正規分布
https://ja.wikipedia.org/wiki/%E6%AD%A3%E8%A6%8F%E5%88%86%E5%B8%83
3σとは何ですか?
https://detail.chiebukuro.yahoo.co.jp/qa/question_detail/q1434162719
さまざまな確率分布
http://www.biwako.shiga-u.ac.jp/sensei/mnaka/ut/statdist.html
実際の事象におけるデータの分布と確率分布、一部のデータから全体を推測する考え方
https://www.marketechlabo.com/probability-inferential-statistics/
統計web:統計学の時間
https://bellcurve.jp/statistics/course/
数学記号の表
https://ja.wikipedia.org/wiki/%E6%95%B0%E5%AD%A6%E8%A8%98%E5%8F%B7%E3%81%AE%E8%A1%A8
数式記号の読み方・表し方
http://izumi-math.jp/sanae/report/suusiki/suusiki.htm